Drum Transcription
Contents
Drum Transcription#
Automatic drum transcription (ADT) aims at extracting note onsets of percussion instrument events from a music recording. An accurate ADT system enables diverse applications in music education, music production, music search and recommendation, and computational musicology.
Limitations of existing ADT models#
There are over 500 percussion instruments that exist around the world and new ones appear all the time. However, most existing ADT systems only focus on transcribing 3 instruments - bass drum, snare drum, and hi-hat. This is again due to the limited number and size of ADT datasets.
More recent approaches leveraging synthetic data and deep neural networks [41][5] expand their output vocabulary to transcribe up to 18 instruments. While it is a significant improvement, 10-20 classes are still far from the wide gamut of percussive instruments used in recorded music. For example, rare or non-western percussion sounds are usually considered out-of-vocabulary. Moreover, when transcribing different datasets, we often need to manually map the percussion instruments in a dataset to the limited output vocabulary of an existing ADT system with reduced granularity. It can also be challenging for ADT systems that utilize fully-supervised learning to generalize to different musical genres or diverse drum sounds. All of these can greatly limit the real-world applicability of ADT. However, further expanding the output vocabulary would typically require a large amount of labeled data per additional class, hence require a lot of annotation effort.
Few-shot ADT#
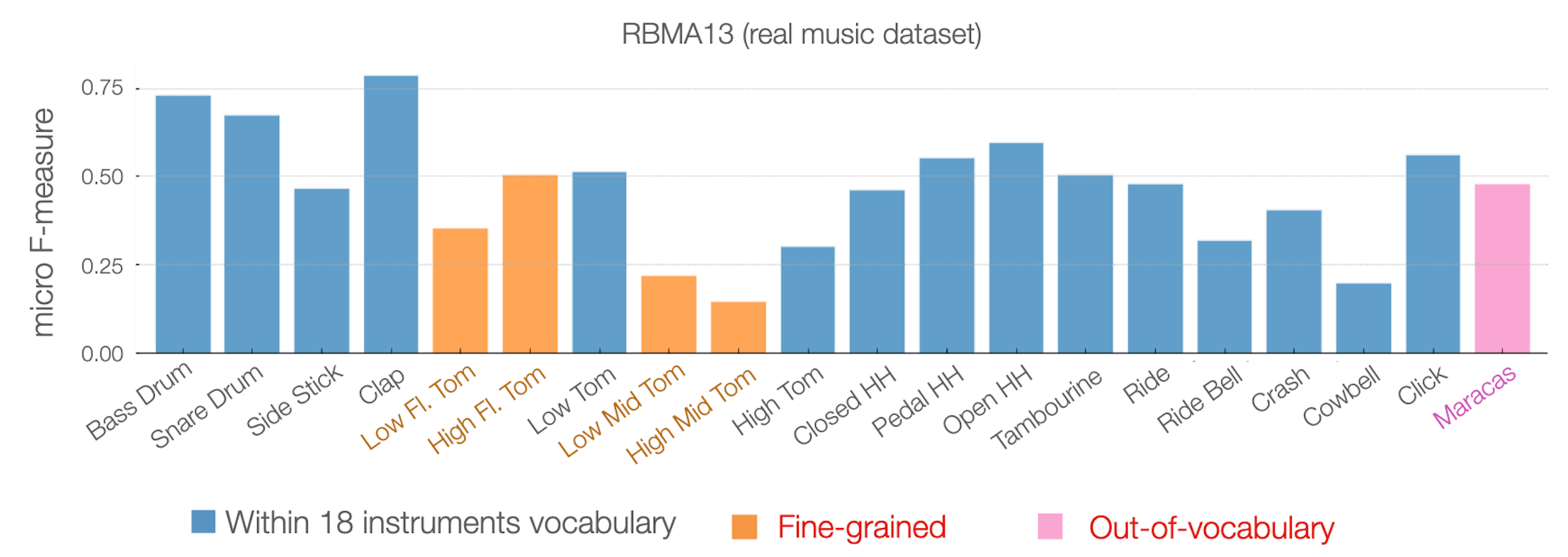
Building on top of the success of few-shot classification among monophonic audio, Wang et al. [10] propose to apply the technique developed in the work of few-shot sound event detection [39] to polyphonic musical audio to perform few-shot ADT, achieving open-vocabulary ADT based on few labeled data. They frame the drum transcription task as a per-frame binary sound classification task, each targeting one instrument. With a few-shot model, pre-trained on percussion instruments from a large synthetic dataset [6], we can transcribe any percussion instrument of interest by providing a few examples of the target.
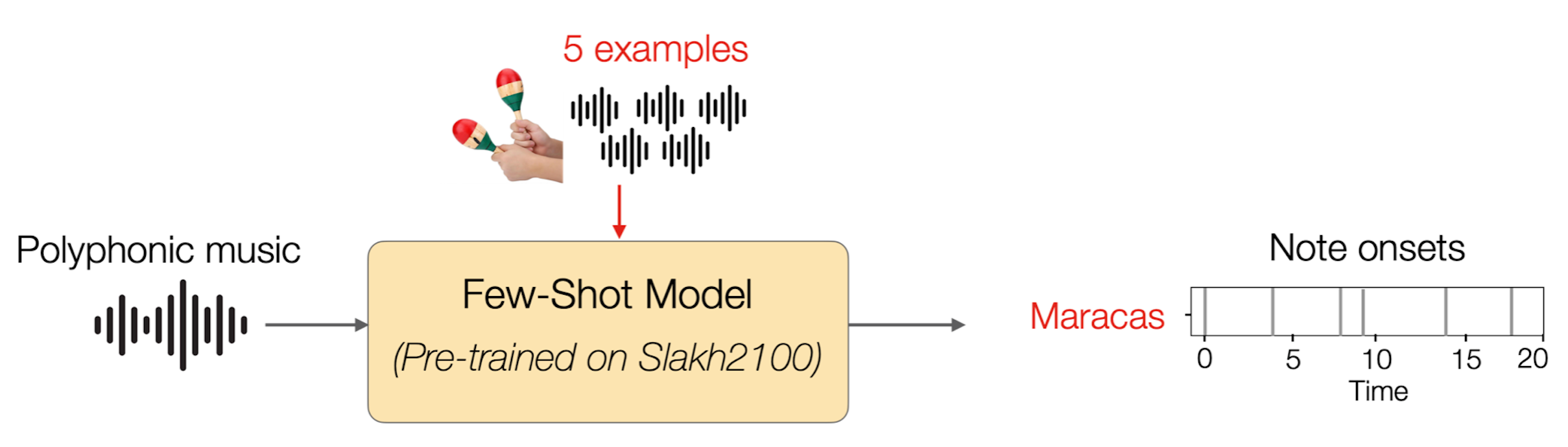
The proposed few-shot ADT framework is evaluated on multiple real-world ADT datasets with polyphonic accompaniment. The result shows that, given just a handful of selected examples at inference time, the few-shot approach can match and in some cases outperform a state-of-the-art supervised ADT model under a fixed vocabulary setting. At the same time, the few-shot model can successfully generalize to finer-grained or extended vocabularies unseen during training, a scenario where supervised approaches cannot operate at all.