What is Few-Shot Learning (FSL) and Zero-Shot Learning (ZSL)?
Contents
What is Few-Shot Learning (FSL) and Zero-Shot Learning (ZSL)?#
Before we dive right into FSL and ZSL, we would like to start with a brief discussion about the labeled data scarcity problem in MIR, to illustrate the motivation and relevance of few-shot and zero-shot learning.
The Scarcity Issue for Labeled Data in MIR#
Deep learning has been highly successful in data-intensive applications, but is often hampered when the dataset is small. A deep model that generalizes well typically needs to be trained on a large amount of labeled data. However, most MIR datasets are small in size compared to datasets in other domains, such as image and text. This is not only because collecting musical data may be riddled with copyright issues, but annotating musical data can also be very costly. The annotation process often requires expert knowledge and takes a long time as we need to listen to audio recordings multiple times. Therefore, many current MIR studies are built upon relatively small datasets with less-than-ideal model generalizability. MIR researchers have been studying strategies to tackle this scarcity issue for labeled data. These strategies can be roughly summarized into two categories:
Data: crowdsourcing [1][2], data augmentation [3][4], data synthesis [5][6], etc.
Learning Paradigm: transfer learning [7], semi-supervised learning [8][9], etc.
However, there are different challenges for each of these approaches. For example, crowdsourcing still requires a large amount of human effort with potential label noise, the diversity gain from data augmentation is limited, and models trained on synthetic data might have issues generalizing to real-world audio. Even with the help of transfer learning or unsupervised learning, we often still need a significant amount of labeled data (e.g. hundreds of thousands of examples) for the target downstream tasks, which could still be hard for rare classes.
FSL and ZSL#
Few-shot learning (FSL) and zero-shot learning (ZSL), on the other hand, tackle the labeled data scarcity issue from a different angle. They are learning paradigms that aim to learn a model that can learn a new concept (e.g. recognize a new class) quickly, based on just a handful of labeled examples (few-shot) or some side information or metadata (zero-shot).
An example#
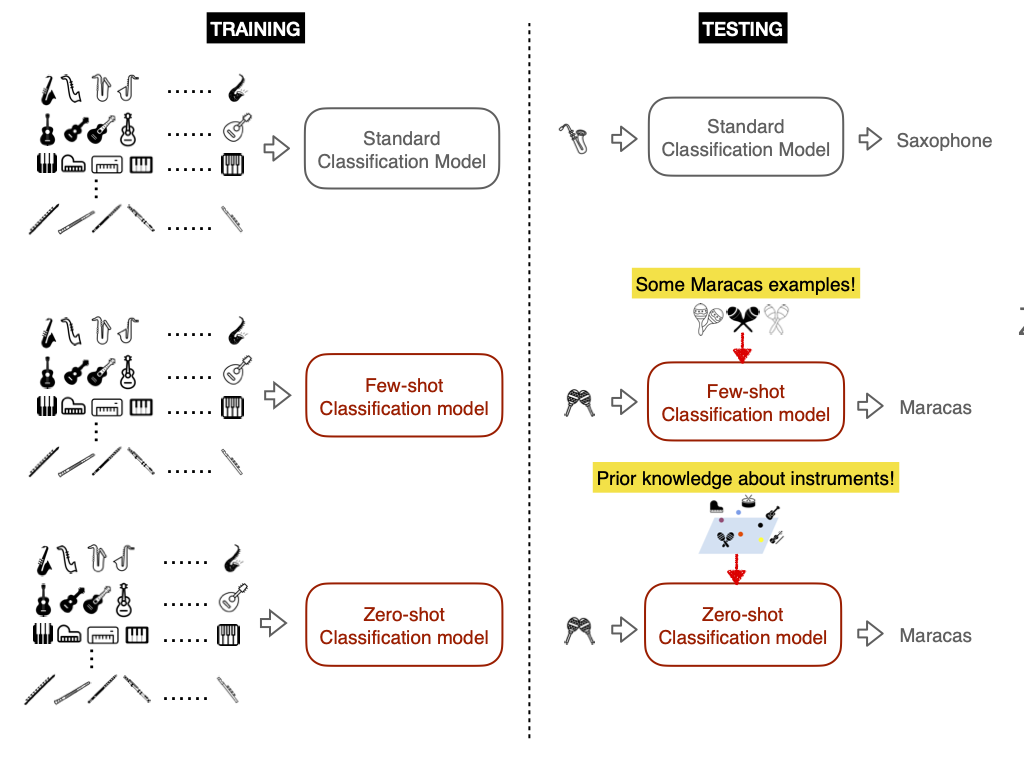
To have a better idea of how FSL and ZSL differ from standard supervised learning, let’s consider an example of training a musical instrument classifier. We assume that there is an existing dataset in which we have abundant labeled examples for common instruments.
In a standard supervised learning scenario, we train the classification model on the training set
(guitar, piano), then at test time, the model classifies “new examples” of “seen classes”(guitar, piano).In a few-shot learning scenario, we also train the model with the same training set that is available
(guitar, piano). But at test time, the goal is for the few-shot model to recognize “new examples” from “unseen classes” (like(banjo, kazoo)) by providing a very small amount of labeled examples.In a zero-shot learning scenario, we train the model on the available training set
(guitar, piano). But at test time, the goal is for the zero-shot model to recognize “new examples” from “unseen classes” (like(banjo, kazoo)) by providing some side information or metadata (e.g. the instrument family, e.g. string, wind, percussion, etc.) or a text embedding.