Side Information
Contents
Side Information#
We will now go over the broad categories of side information (attribute-based, term or description-based, and etc.) and look through specific examples from three different domains (computer vision, language, and audio). Since zero-shot learning has been mainly studied in computer vision domain, there are relatively more benchmark datasets available for the image classification task. However, we seek to discuss the future direction of music-related zero-shot learning datasets by going over the formation of image-related ones.
Types of Side information#
(1) Class-Attribute relationship#
The first type of side information bases on the class-attribute relationships. Using the attribute information, we can build the vector representation of a class, which can be further put into the zero-shot learning framework.
In computer vision domain, multiple attribute-annotated image class datasets are available.
Animals with Attributes dataset [27]
Image annotations of 50 different animal classes with 85 labeled attributes.


Caltech-UCSD Birds 200 Dataset [28]
Image annotations of 200 bird species with a bounding box, a rough bird segmentation, and a set of attribute labels.
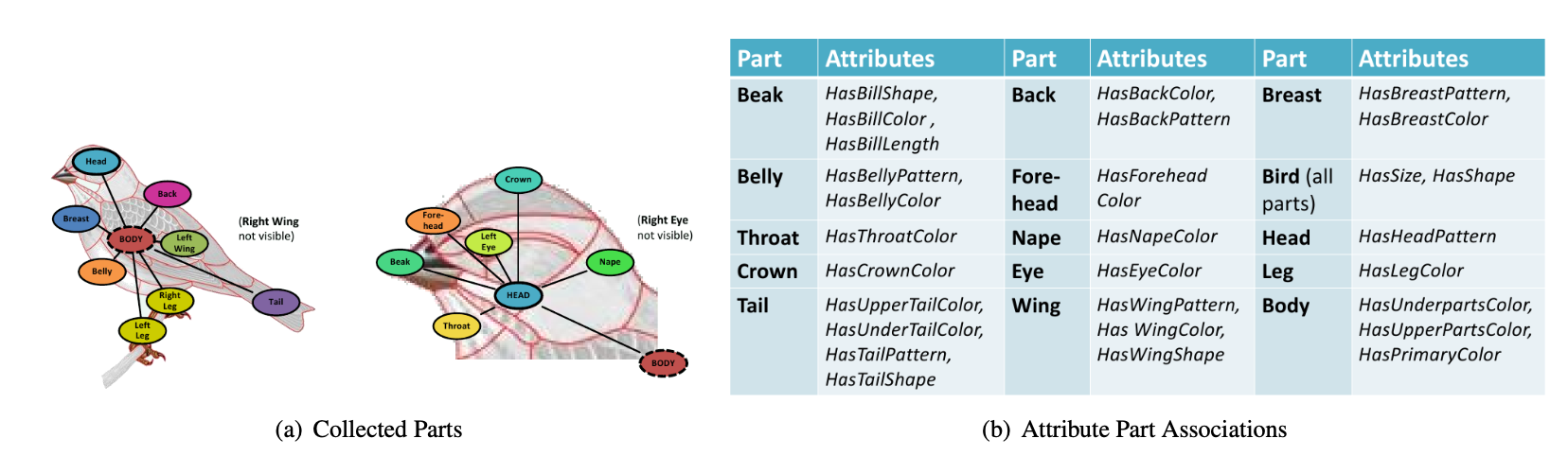
In music domain, there aren’t many datasets containing the human annotated class-attribute relationship. However, we can find an example that has combined two labeled music datasets, OPEN-MIC 2018 and Free Music Archive (FMA) to formulate statistical instrument attribute scores for each genre class.
Instrument-genre dataset : OPEN-MIC 2018 instrument annotation combined with FMA genre annotations. [29]
Audio annotations of 157 genre labels with each genre annotated with likelihood measures of 20 instruments.
FMA contains audio files and genre annotations. OpenMIC-2018, which was originally designed for multiple instrument recognition, has 20 different instrument annotations to the audio files in FMA.

(2) Class as a textual datapoint#
Since the label classes themselves are in a textual form, information retrived from various textual sources can also be used as the side information.
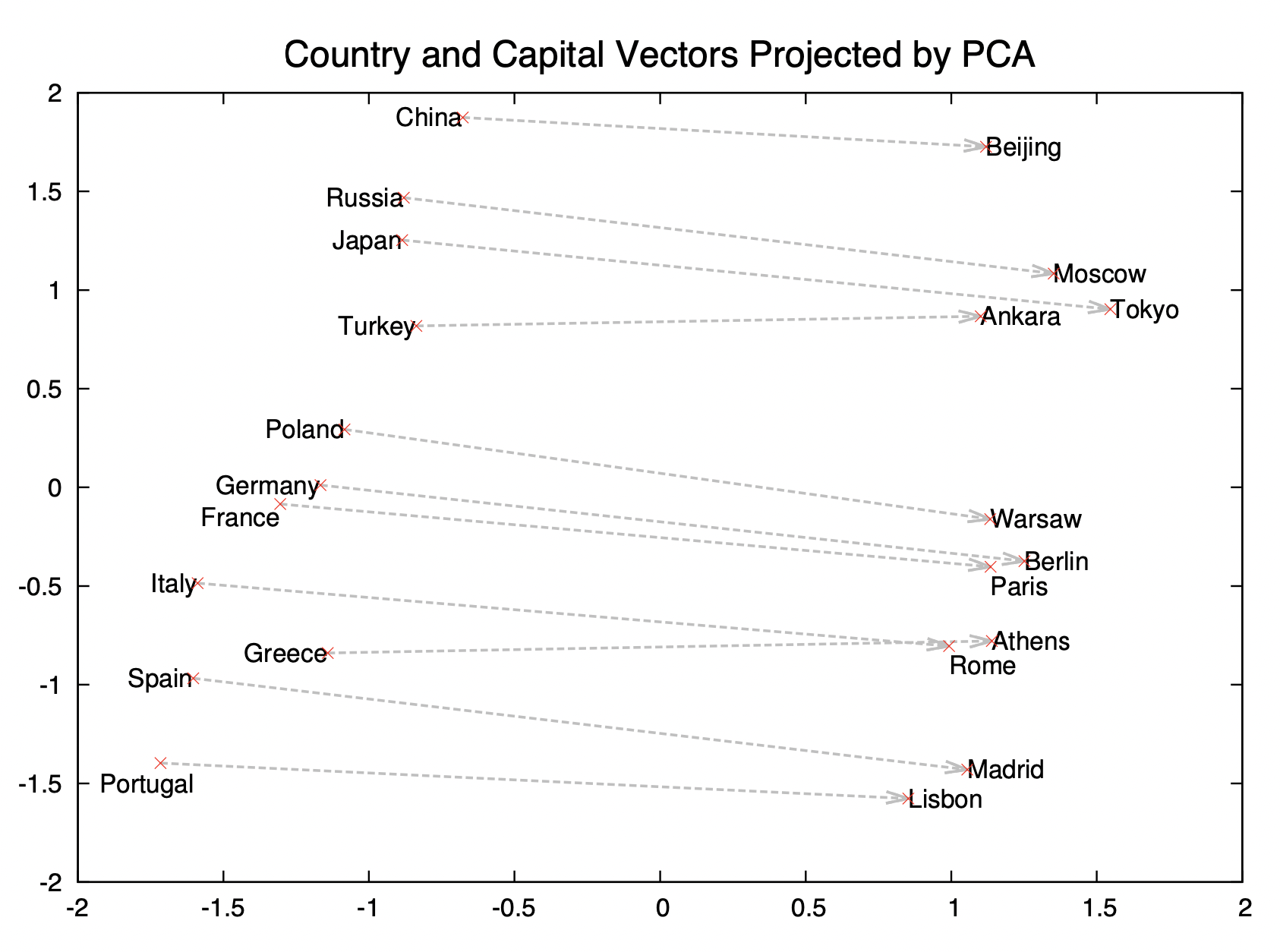
For example, Wordnet hierarchy provides the general semantic relationship between words and the articles in Wikipedia provide the detailed description of each class label. We can also conjugate a general word embedding space trained with a large textual corpus (Word2vec or GloVe), and this can be extended to more sophisticated modern language models such as BERT.
General word semantic spaces#
Music word semantic space#
In music domain, following resources have been used for the zero-shot genre or tag classification experiments.
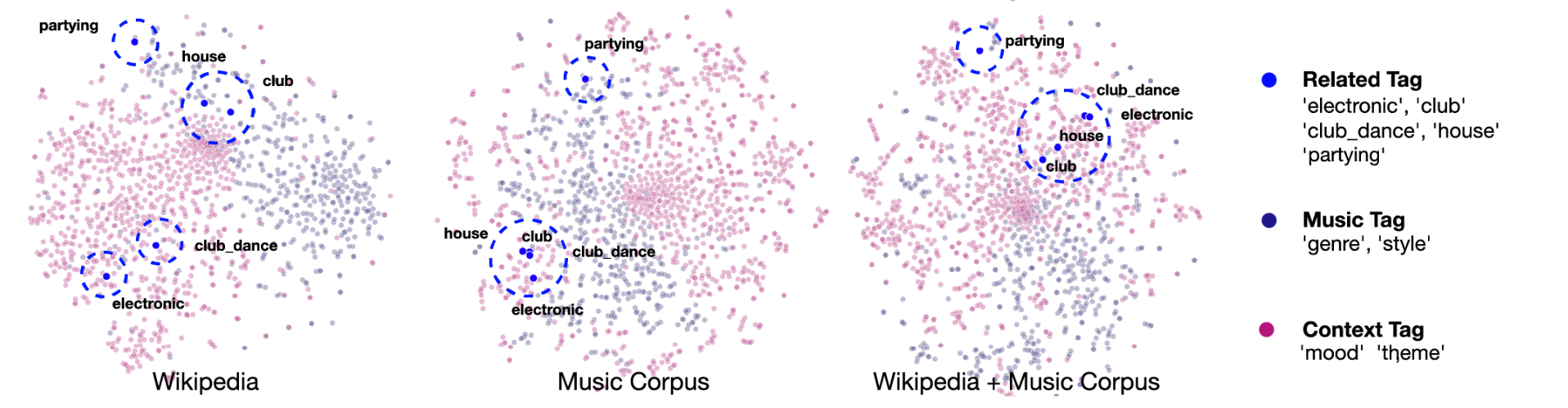
Word-level semantic space. [33]
Musical word embedding
(3) Class attributes from other modalities.#
Music-related images#
Music audio with tag annotations and album cover images
Track audio with corresponding album cover images
MuMu dataset : 31k albums with cover images classified into 250 genre classes. [34]
Instrument images with annotations.
PPMI datset [35]


Can be used combined with instrument audio datasets. Check out our hands-on tutorial example!