Sampling Few-Shot Learning Episodes
Contents
Sampling Few-Shot Learning Episodes#
Last chapter, we learned how to create a class-conditional dataset for few-shot learning, and we implemented our own class-conditional version of the TinySOL dataset.
This chapter, we will learn how to create an Episodic Dataset for a Class Conditional Dataset, and use it sample few-shot learning episodes.
To recap on our foundations chapter, episodic training is a technique used in few-shot learning to effectively leverage a large training dataset. It involves splitting each training iteration into a self-contained learning task, known as an episode, which simulates a few-shot learning scenario with a small number of labeled examples for a set of classes.
During episodic training, the model is presented with a completely new \(N\)-shot, \(K\)-way classification task at each step, and must learn to classify the examples in the query set using only the labeled examples in the support set. This allows the model to learn how to effectively learn from a small amount of data and adapt to new tasks quickly.
Anatomy of an Episode#
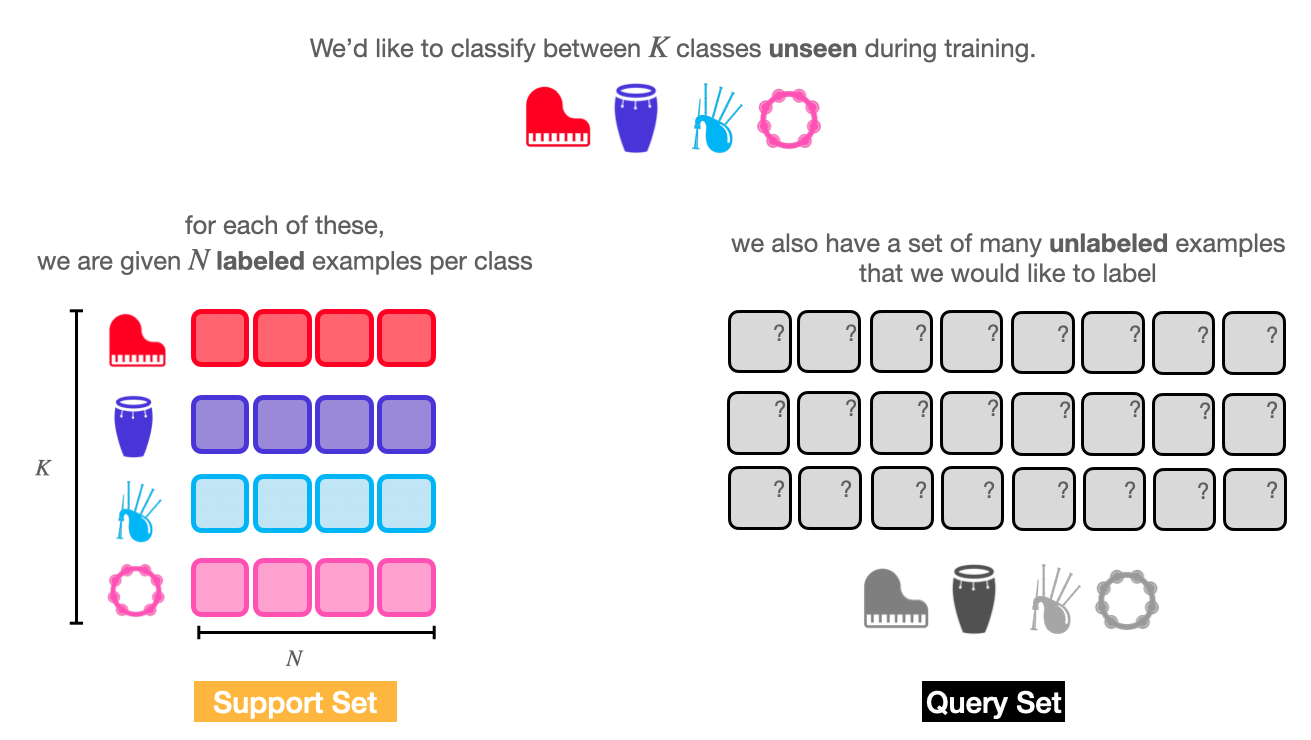
Fig. 8 A few-shot learning episode splits data into two separate sets: the support set (the few labeled examples of novel data) and the query set (the data we want to label).#
In few-shot learning, an episode consists of two sets of data: the support set and the query set.
The support set contains a small number of labeled examples for each of the classes in the episode. We use the examples in the support set to guide the few-shot learning model in the classification task.
The query set contains a larger number of (unlabeled) examples for each of the classes. During training, we make predictions for examples in the query set, and compute a loss over these predictions to update the model parameters. During evaluation, we use the predictions for the query set to compute any evaluation metrics for the episode.
Requirements (hidden)
%%capture
!pip install torch
!pip install --no-cache-dir --upgrade music-fsl
import random
import torch
from music_fsl.data import ClassConditionalDataset
import music_fsl.util as util
Building an EpisodeDataset class#
To sample few-shot learning episodes, we’ll be writing a dataset class called EpisodeDataset that will act as a wrapper around a ClassConditionalDataset.
Just like any other PyTorch dataset, we’ll have to implement the __len__ and __getitem__ methods.
Let’s start by writing an __init__ method, which will be responsible for initializing the episode dataset.
We’ll add in the ability to specify the number of classes to sample per episode (n_way), the number of support examples to sample per class (n_support), and the number of query examples to sample per class (n_query). We’ll also add in the ability to specify the number of episodes to sample (n_episodes).
class EpisodeDataset(torch.utils.data.Dataset):
"""
A dataset for sampling few-shot learning tasks from a class-conditional dataset.
Args:
dataset (ClassConditionalDataset): The dataset to sample episodes from.
n_way (int): The number of classes to sample per episode.
Default: 5.
n_support (int): The number of samples per class to use as support.
Default: 5.
n_query (int): The number of samples per class to use as query.
Default: 20.
n_episodes (int): The number of episodes to generate.
Default: 100.
"""
def __init__(self,
dataset: ClassConditionalDataset,
n_way: int = 5,
n_support: int = 5,
n_query: int = 20,
n_episodes: int = 100,
):
self.dataset = dataset
self.n_way = n_way
self.n_support = n_support
self.n_query = n_query
self.n_episodes = n_episodes
Sampling episodes: the __getitem__ method#
Next, we will implement the __getitem__ method. This method will be responsible for generating the actual episodes for training and evaluation.
def __getitem__(self, index: int) -> Tuple[Dict, Dict]:
"""Sample an episode from the class-conditional dataset.
We’ll start by creating a random number generator based on the index of the episode we want to sample. This will allow us to sample the same episode every time we call __getitem__ with the same index.
rng = random.Random(index)
First, we need to find out which subset of the classlist will be in the episode. We can do this by sampling n_way classes from the classlist.
# sample the list of classes for this episode
episode_classlist = rng.sample(self.dataset.classlist, self.n_way)
Next, we need to sample the support and query sets for each class. We can start creating empty lists for each set, and iterating through each of the classes:
# sample the support and query sets for this episode
support, query = [], []
for c in episode_classlist:
We need to sample n_support and n_query examples for each class. Because our dataset is an instance of a Class Conditional Dataset, we can use the class_to_indices attribute to get the indices of the examples for each class.
# grab the dataset indices for this class
all_indices = self.dataset.class_to_indices[c]
Once we have a hold of all the indices for that given class (c), we can grab n_support + n_query items from the dataset.
# sample the support and query sets for this class
indices = rng.sample(all_indices, self.n_support + self.n_query)
items = [self.dataset[i] for i in indices]
We can add the class target to each item we sampled.
NOTE: the index of the target is with respect to the episode_classlist. This is important, since we will use this index later to calculate the cross-entropy loss during training.
# add the class label to each item
for item in items:
item["target"] = torch.tensor(episode_classlist.index(c))
Then, we can split all the items we sampled into support and query items.
# split the support and query sets
support.extend(items[:self.n_support])
query.extend(items[self.n_support:])
Finally, we will collate the items in each set into a dictionary, to make batch processing possible. Since the details of writing a collating function aren’t covered here, we invite the reader to check out the PyTorch Dataset docs for more information.
# collate the support and query sets
support = util.collate_list_of_dicts(support)
query = util.collate_list_of_dicts(query)
support["classlist"] = episode_classlist
query["classlist"] = episode_classlist
return support, query
Expand the cell below to see the full implementation of the EpisodeDataset class.
from typing import Tuple, Dict
class EpisodeDataset(torch.utils.data.Dataset):
"""
A dataset for sampling few-shot learning tasks from a class-conditional dataset.
Args:
dataset (ClassConditionalDataset): The dataset to sample episodes from.
n_way (int): The number of classes to sample per episode.
Default: 5.
n_support (int): The number of samples per class to use as support.
Default: 5.
n_query (int): The number of samples per class to use as query.
Default: 20.
n_episodes (int): The number of episodes to generate.
Default: 100.
"""
def __init__(self,
dataset: ClassConditionalDataset,
n_way: int = 5,
n_support: int = 5,
n_query: int = 20,
n_episodes: int = 100,
):
self.dataset = dataset
self.n_way = n_way
self.n_support = n_support
self.n_query = n_query
self.n_episodes = n_episodes
def __getitem__(self, index: int) -> Tuple[Dict, Dict]:
"""Sample an episode from the class-conditional dataset.
Each episode is a tuple of two dictionaries: a support set and a query set.
The support set contains a set of samples from each of the classes in the
episode, and the query set contains another set of samples from each of the
classes. The class labels are added to each item in the support and query
sets, and the list of classes is also included in each dictionary.
Yields:
Tuple[Dict[str, Any], Dict[str, Any]]: A tuple containing the support
set and the query set for an episode.
"""
# seed the random number generator so we can reproduce this episode
rng = random.Random(index)
# sample the list of classes for this episode
episode_classlist = rng.sample(self.dataset.classlist, self.n_way)
# sample the support and query sets for this episode
support, query = [], []
for c in episode_classlist:
# grab the dataset indices for this class
all_indices = self.dataset.class_to_indices[c]
# sample the support and query sets for this class
indices = rng.sample(all_indices, self.n_support + self.n_query)
items = [self.dataset[i] for i in indices]
# add the class label to each item
for item in items:
item["target"] = torch.tensor(episode_classlist.index(c))
# split the support and query sets
support.extend(items[:self.n_support])
query.extend(items[self.n_support:])
# collate the support and query sets
support = util.collate_list_of_dicts(support)
query = util.collate_list_of_dicts(query)
support["classlist"] = episode_classlist
query["classlist"] = episode_classlist
return support, query
def __len__(self):
return self.n_episodes
def print_episode(self, support, query):
"""Print a summary of the support and query sets for an episode.
Args:
support (Dict[str, Any]): The support set for an episode.
query (Dict[str, Any]): The query set for an episode.
"""
print("Support Set:")
print(f" Classlist: {support['classlist']}")
print(f" Audio Shape: {support['audio'].shape}")
print(f" Target Shape: {support['target'].shape}")
print()
print("Query Set:")
print(f" Classlist: {query['classlist']}")
print(f" Audio Shape: {query['audio'].shape}")
print(f" Target Shape: {query['target'].shape}")
Putting it Together: Sampling an Example Episode#
Let’s grab the class-conditional TinySol we created last chapter, and use the EpisodeDataset to sample an episode from it.
%%capture
from music_fsl.data import TinySOL
dataset = TinySOL()
# create an episodic dataset
episodes = EpisodeDataset(
dataset,
n_way=5,
n_support=5,
n_query=20,
n_episodes=100,
)
support, query = episodes[0]
episodes.print_episode(support, query)
Support Set:
Classlist: ['Accordion', 'Violin', 'Oboe', 'Bassoon', 'Alto Saxophone']
Audio Shape: torch.Size([25, 1, 16000])
Target Shape: torch.Size([25])
Query Set:
Classlist: ['Accordion', 'Violin', 'Oboe', 'Bassoon', 'Alto Saxophone']
Audio Shape: torch.Size([100, 1, 16000])
Target Shape: torch.Size([100])
In this chapter, we learned how to create an EpisodicSampler class that extends the Sampler class in PyTorch to sample few-shot learning episodes.
The EpisodicSampler allows us to specify the number of classes to sample per episode, the number of support and query examples to sample per class, and the number of episodes to sample. It iterates over the episodes and yields a support and query set for each episode, where the support set contains labeled examples for each of the classes in the episode and the query set contains unlabeled examples for each of the classes. This allows us to use the EpisodicSampler to generate few-shot learning tasks for training and evaluation.
Next, we’ll write code to create a Prototypical Network model that can be trained on the episodes generated by the EpisodicSampler.